The next episode of my deep clambering into the underbelly of ARC starts from this Tweet by @steipete where he says “With ARC, I now find myself typing “new” for dumb model objects. Yay or Nay?“. It got me thinking. He’s totally right that with ARC we can now just use [SomeClass new] and let ARC handle all the memory management for us. Previously we’d often create a convenience class method on SomeClass which would return an object autoreleased so that it made the calling code clean and easy to understand the memory management. Now with ARC we don’t need to do that and I wondered what would be the benefit of using new over alloc + init over using our old friends, the convenience class methods. This blog post tells that story.
Some background on new
First we’ll take a look at what new actually does. According to the Apple documentation, it does this:
Allocates a new instance of the receiving class, sends it an init message, and returns the initialized object.
So we should expect a call like [SomeClass new] to be equivalent to [[SomeClass alloc] init]. The memory management here tells us that the returned object is owned by the caller, i.e. it’s returned with a +1 retain count. In the days of pre-ARC, we would therefore have to release this object when we were done with it. ARC adds these in for us as we know.
What’s being tested
What I wanted to know is which is faster out of these methods:
-
[[SomeClass alloc] init] -
[SomeClass new] -
[SomeClass giveMeAnObject] -
[SomeClass newObject]
Where giveMeAnObject is a convenience method to return an object autoreleased and newObject is a convenience method which we would hope is the same as the standard new.
How to test
In order to benchmark each of these methods I decided to time how long it would take to call each of them a given number of times with correct memory management (well, I have no choice if ARC is enabled). I used this method for timing which gives me the number of nanoseconds that my code took to execute:
1 2 3 4 5 6 7 8 | |
In order to test this and to ensure there’d be no shortcuts made by the compiler / runtime by using an NSString or an NSNumber I created a simple dummy class called ClassA like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Then to benchmark each one I decided to loop for a number of iterations ranging from 1000 to 10000000 for each style of creating an instance of ClassA. Each of these should have the exact same effect, but we’d like to know how they differ in speed. Below is the code I used, commenting out all but one of the ClassA *x = each time I did the test.
1 2 3 4 5 6 | |
For each of these tests I used my iPhone 4 (so ARMv7), running iOS 5.0.1 and compiled the code at O3.
The results are in!
Below are the results of running the tests. The value under each column is the time taken in milliseconds for the number of iterations given on the left.
| A | B | C | D | |
|---|---|---|---|---|
| 1000 | 2.264 | 2.349 | 2.199 | 2.394 |
| 5000 | 10.102 | 10.149 | 9.993 | 11.017 |
| 10000 | 19.180 | 20.148 | 19.509 | 20.036 |
| 50000 | 92.357 | 98.177 | 104.362 | 97.099 |
| 100000 | 185.054 | 199.825 | 204.560 | 194.353 |
| 500000 | 924.090 | 1000.588 | 1335.106 | 985.735 |
| 1000000 | 1863.110 | 1973.086 | 2885.719 | 1977.487 |
| 5000000 | 9407.941 | 10245.857 | 23314.495 | 9757.074 |
| 10000000 | 18557.632 | 20841.905 | 56602.491 | 20315.784 |
And graphically, that looks like this:
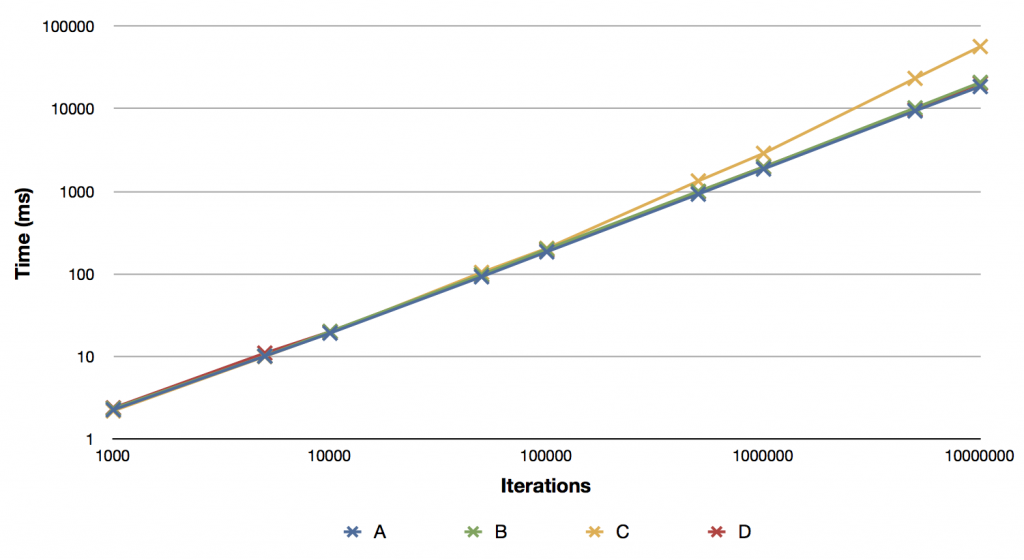
So what does that tell us then? Well it basically tells us that alloc + init is fastest, with new and our custom convenience new close behind. It also shows us that for large iterations, our convenience method that returns the value autoreleased is quite a bit slower. At the maximum number of iterations, it was more than twice as slow as the other methods.
Let’s analyse what happened then
In order to understand what’s going on here, let’s take a look at the code generated. Below are the various interesting bits of code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
1 2 3 4 5 6 7 8 9 10 | |
So having looked at all the relevant code it might be surprising that these are that different. They’re all going to have a similar number of instructions. Infact method A has in the inner loop more instructions, but it was the fastest. The interesting question is why is method C so much slower than the others for large number of iterations? If we take a look at the generated code for method C we’ll notice that there’s a call to objc_retainAutoreleasedReturnValue. This method is a kind of shortcut to retain a value that will have been returned autoreleased. It should be working with our code since all of this is compiled using ARC and running on an iOS 5 device. It was interesting to me then that this method took twice as long at large numbers of iterations. I can understand that it’s likely to be slower since there’s more message dispatch going on, but I did not expect it to be that much slower and also interesting that the difference increase with increasing number of iterations.
Conclusions
I’m actually at a loss as to how to explain why method C is so much slower. It’s great to see that A, B and D are roughly the same speed, which is of course what we would expect. This whole thing does mean that we are much better off using See below for a reasoning for why method C was slower and how method C can become just as fast as the other methods.new, alloc + init or a convenience method that returns an object with a +1 retain count rather than using convenience methods that return the object autoreleased.
Ah ha! That’s why!
Having done a bit more digging I have found why method C was so much slower. Whilst I was writing this up I thought it was a bit odd that the tail call in giveMeAnObject was to objc_autorelease rather than objc_autoreleaseReturnValue. The magic of objc_retainAutoreleasedReturnValue which I refer to previously only works if the value has been returned with objc_autoreleaseReturnValue. The internals of that are for a later blog post but just take it from me that it works like that. So I decided to just change the return type of giveMeAnObject from ClassA* to id. I thought that this should make absolutely no difference. I was wrong. Take a look and see:
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
The single difference here is the call to objc_autoreleaseReturnValue rather than objc_autorelease. I still don’t particularly understand why the compiler is doing something different here, so I’ve still to work that one through but The results for the benchmark using this method are as follows (added to the previous results where I’ve called this new method, E):
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1000 | 2.264 | 2.349 | 2.199 | 2.394 | 2.401 |
| 5000 | 10.102 | 10.149 | 9.993 | 11.017 | 11.381 |
| 10000 | 19.180 | 20.148 | 19.509 | 20.036 | 22.120 |
| 50000 | 92.357 | 98.177 | 104.362 | 97.099 | 106.966 |
| 100000 | 185.054 | 199.825 | 204.560 | 194.353 | 223.045 |
| 500000 | 924.090 | 1000.588 | 1335.106 | 985.735 | 1113.261 |
| 1000000 | 1863.110 | 1973.086 | 2885.719 | 1977.487 | 2262.960 |
| 5000000 | 9407.941 | 10245.857 | 23314.495 | 9757.074 | 11419.025 |
| 10000000 | 18557.632 | 20841.905 | 56602.491 | 20315.784 | 22510.462 |
So that at least explains why method C was so much slower. But I’ve no idea why the compiler doesn’t emit the same thing when the return type of giveMeAnObject is ClassA* or id.
Update: Turns out, it’s a bug
It turns out that it’s a bug that the compiler (well, the optimiser part of the compiler) did something different for the case of returning id versus ClassA* and the cases of splitting out the alloc + init in the method versus returning on the same line. All of these should compile exactly the same, but they don’t in the current version of clang.